在前端开发中,我们经常需要定位一个元素。如tooltip、popover或者modal等,或许是我们需要将它们定位在依赖元素的周围或屏幕滚动屏幕中心位置。这对于前端开发的码农来说并不是难事。算出和依赖元素的offset,设置元素的left、right。对于稍复杂的场景我们可能需要考虑被positioned的祖先元素。
但往往不是所有的事情都是这么简单的。笔者最新在项目开发中就遇见这样一个问题:这里的HTML是嵌入的,其来自jpedal商业软件从PDF文件自动生成的;为了展示的样式,jpedal统一使用了 position:absolute和relative来定位PDF元素。然而由于业务的需求,我们需要操作这类HTML。其中一个需求就是需要在每段文字附近显示操作工具条。
对于这类未知的DOM定位,那么我们就需要遍历它的DOM树来计算它的相对位置了。行为下面的这段代码:
function isStaticPositioned(element) {
return (getStyle(element, 'position') || 'static' ) === 'static';
}
var parentOffsetEl = function(element) {
var docDomEl = $document[0];
var offsetParent = element.offsetParent || docDomEl;
while (offsetParent && offsetParent !== docDomEl && isStaticPositioned(offsetParent) ) {
offsetParent = offsetParent.offsetParent;
}
return offsetParent || docDomEl;
};
在这里,我们会根据元素递归查询它所在的的DOM树中被positioned的最接近的祖先元素,然后才计算它们的相对位置。
这是一段来自Angular-UI bootstrap的$position服务的源码。这也是本文将要提到的获取定位元素位置的法宝。其源码位置在https://github.com/angular-ui/bootstrap/blob/master/src/position/position.js。
在$position服务中为我们提供了3个有用的位置服务:position、offset和positionElements。position是计算具体元素的定位位置,返回一个带有width、height、top、left的对象;positionElements则是返回某元素相对于其依赖容器元素的定位位置,一个带有top、left的对象。
笔者为了测试这写API,在jsbin中写了一个特定的指令:
JavaScript:
angular.module("com.ngbook.demo", ['ui.bootstrap.position'])
.directive('position', ['$position', function($position){
return {
restrict: 'EA',
templateUrl: '/position.html',
scope:{
title:"@"
},
link:function(scope, elm, iAttrs){
scope.data = $position.position(elm);
}
};
}]);
HTML:
<script type="text/ng-template" id="/position.html">
<table class="table">
<thead>
<th colspan="2">{{title}}</th>
</thead>
<tbody>
<tr ng-repeat="field in ['width', 'height', 'left', 'top']">
<td>{{field}}</td>
<td>{{data[field] | number}}</td>
</tr>
</tbody>
</table>
</script>
所以我们可以如下测试这类API:
<position title ="no positioned parent"></position>
<div style="position: relative;padding:50px;">
<position title ="relative parent"></position>
<div style="position: absolute;top:250px; padding:50px;">
<position title="relative->absolute parent"></position>
</div>
</div>
<div style="position: absolute;top:0px;left:250px; padding:50px;">
<position title="absolute parent"></position>
</div>
其效果可以在jsbin demo:
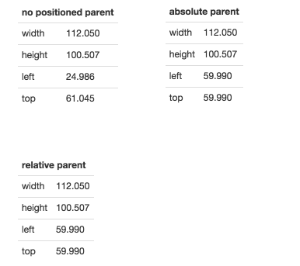
同样你也可以在官方的文档中看见对它的测试: https://github.com/angular-ui/bootstrap/blob/master/src/position/test/test.html。
简单的说:如果我们需要获取某个元素的定位信息,则我们可以用 $position.position(element);获取相对于固定元素的定位,则可以使用$position.positionElements(hostEl, targetEl, positionStr, appendToBody)。其中positionStr是一个横向和纵向的字符串,如:”top-left”、”bottom-left”。其默认值为center。如笔者项目所期望的在某文字段落的左上角显示工具条:
$position.after($toolbar);
var elPosition = $position.positionElements($paragraph, $toolbar, “top-left”);
$toolbar.css({left: elPosition.left + 'px', top: elPosition.top + 'px'});
当然也不要忘记为toolbar元素设置position: absolute;